how to scrape the web
March 31, 2012 3 min read
Many web sites and applications make use of third party data. Ideally we can get this data in structured form from an API (e.g. Google Maps, twitter, etc), but sometimes there is no API available. I was working on a sports web app, and wanted to automatically update scores and odds. This was before ESPN released their API, so for now let's pretend we have no API. How can we go about getting external data in an automated way for use by our app? In much the same way as we would do manually - go to a web site and look. It is a crude, unreliable, somewhat inefficient, and sometimes taboo method called web or screen scraping, but it can work in a pinch for a smaller app. For this example, I'm going to scrape basketball scores from NBA.com.
Tools required: web browser, developer tools, DOM/HTML parsing library.
The first thing I usually do is examine the structure of the site and the pages I want to scrape from. In the case of NBA's site, I can see that the score pages are located at nba.com/gameline/date(yyyymmdd). Then we need to look at the html structure of the score page. Use your favorite browser and dev tool. I am using Firefox and Firebug for this example. Right click on one of the score boxes, and inspect element.

So we can see that each score box is a div with a class of "nbaModTopScore". Similarly the team names and scores are in divs with descriptive class names. Not all sites will be structured this nicely, so it's best if you can find one that has good organization. Now that we know the structure, we need to come up with a query that targets the data we are after. Most sites will already be using jquery or prototype, but if not, you could download the html, add in your favorite library, and work with the local file. NBA.com has jquery, so I can go into my firebug console and try some css selectors.
I start with
$(".nbaModTopTeamAw .nbaModTopTeamName")to target the road/visiting teams, and it returns an array of 8 div nodes.
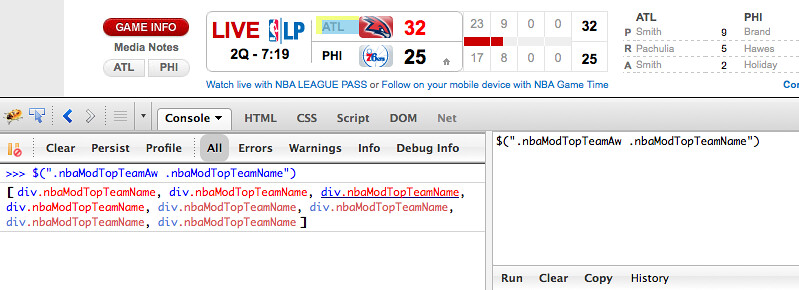
We have 8 games today, so that looks right. To verify, let's output the contents of the node and make sure the team names are there.
$(".nbaModTopTeamAw .nbaModTopTeamName").map(function() { return $(this).html(); });
Yep, looks correct. I repeat this for the home teams and scores. So I've verified I can target the data from javascript, but that won't help much for the server side unless you're using node.js (not a bad idea by the way). Most programming languages have some kind of HTML or XML parsing capability or library. My app was using php, so we need an html parser for php. A quick google search yielded PHP Simple HTML DOM Parser. Using this library, we can grab the html and use the same css selectors to get at the data, and store them in the database. Here's some sample output from the script.

You can find the source code for the full script on github.
This technique can be used to scrape any kind of data you might need for an application. As I mentioned before, it is an inefficient, unreliable method, and should be used as a last resort. An API gives you the raw data in a consistent structure, while scraping requires downloading the full html and parsing through it. You are also screwed if the html is redesigned, which is not uncommon. You would then have to repeat the process on the new html. Another caveat is web sites are increasingly generating dynamic data with javascript, which will not show up in the returned html. With all that said, there may come a time when you just want to occasionally pull some data from a web site, and scraping can get the job done when there are no API options.